本章我们会将开启虚拟地址空间,并将内核从物理地址空间映射到虚拟地址空间上。这样做不仅可以增强安全性,同时也为后续进程的实现提供了方便。
4.1 sv39内核映射
1、RV64 中,页表的实现主要有两种:Sv39 和 Sv48。这里我们采用 Sv39 作为我们的页表实现。
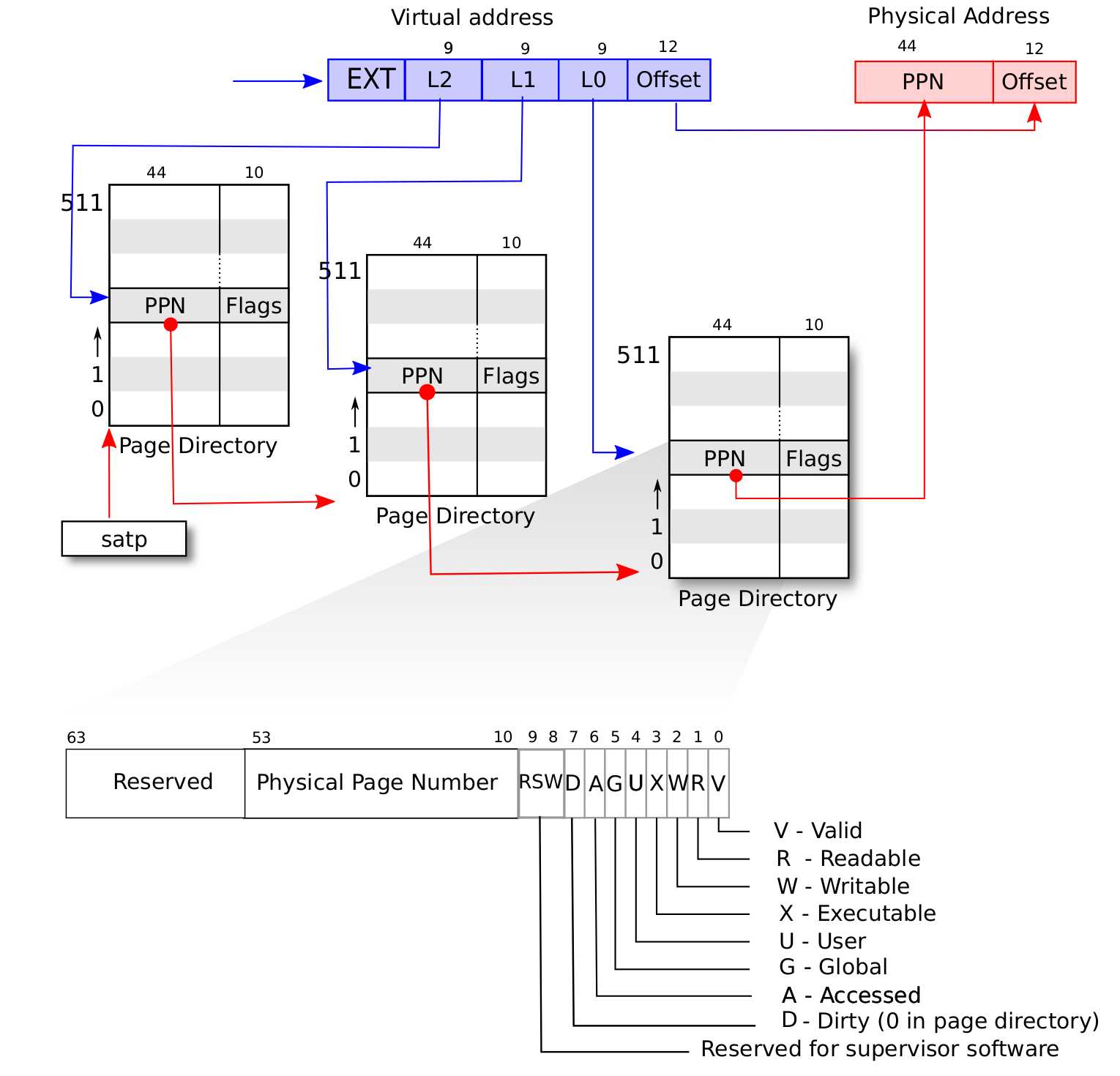
- 在 Sv39 中,物理地址有 56 位,而虚拟地址有 64 位。虽然虚拟地址有这么多位,但是其中只有低 39 位有效,第 63 ~ 39 位的值必须等于第 38 位
- 页表中的每一项即为页表项(Page Table Entry)
2、在这之前,我们的操作系统内核虚拟地址和物理地址是一致的,在此之后,我们将为操作系统添加一个偏移量0xffffffff000000000,让内核运行在起始地址为0xffffffff80200000的虚拟地址空间,这意味着我们需要将内核的所有地址向高地址空间平移,这是一种线性映射的方式
- 我们通过修改链接脚本的一些参数来达成这个目的:
// kernel/kernel.ld
/* 目标架构 */
OUTPUT_ARCH(riscv)
/* 执行入口 */
ENTRY(_start)
/* 数据存放起始虚拟地址 */
BASE_ADDRESS = 0xffffffff80200000;
SECTIONS
{
/* . 表示当前地址(location counter) */
. = BASE_ADDRESS;
/* start 符号表示全部的开始位置 */
kernel_start = .;
. = ALIGN(4K);
text_start = .;
/* .text 字段 */
.text : {
/* 把 entry 函数放在最前面 */
*(.text.entry)
/* 要链接的文件的 .text 字段集中放在这里 */
*(.text .text.*)
}
. = ALIGN(4K);
rodata_start = .;
/* .rodata 字段 */
.rodata : {
/* 要链接的文件的 .rodata 字段集中放在这里 */
*(.rodata .rodata.*)
}
. = ALIGN(4K);
data_start = .;
/* .data 字段 */
.data : {
*(.data .data.*)
}
. = ALIGN(4K);
bss_start = .;
/* .bss 字段 */
.bss : {
*(.sbss .bss .bss.*)
}
/* 内核结束地址 */
. = ALIGN(4K);
kernel_end = .;
}- 修改了
BASE_ADDRESS为虚拟地址 - 将每个段都和 4K 字节对齐,也就是和页边界对齐。这样的好处是,不会有一个页同时包含两个不同段的内容,每个页都只包含唯一的一个段,便于设置这个页的权限。
3、将在3.3节-memory.h中定义的内核起始虚拟地址重新在consts.h中定义,再定义线性映射偏移常量
// kernel/consts.h
// 内核起始的虚拟地址
#define KERNEL_BEGIN_VADDR 0xffffffff80200000
// 内核地址线性映射偏移
#define KERNEL_MAP_OFFSET 0xffffffff00000000- 设置完成链接脚本后,让我们再次思考当 OpenSBI 运行结束后,跳转到物理地址 0x80200000 时,内核运行的状况:
- PC 指向 0x80200000,CPU 此时无论是取址还是访存都是直接访问物理内存的
- 内核被放置在 0x80200000 开头的物理地址空间,但是内核觉得自己是运行在 0xffffffff80200000 开头的地址空间上
- 怎么去理解呢?即OpenSBI跳转到
0x80200000开始运行代码,只要不遇到跳转指令均可以正常工作,因为一旦遇到跳转的指令,内核代码是从0xffffff80200000开始存放的,故会跳转到虚拟地址的指令位置处。 - 比如在
entry.S的程序文件中,会跳转到main去执行,此时main存放在高地址空间,CPU 依照此时的模式却会把它当成一个物理地址来正常地寻址,那自然是找不到的。 - 所以在执行跳转之前,我们需要设置一番。具体的,就是设置一个页表空间,并且将其基地址物理页号写入 satp 寄存器,并设置 Sv39 模式。
4、设置页表:我们在内核初始化的过程中就需要设置好映射机制,所以要修改entry.S
// kernel/entry.S
.section .text.entry // 内核的入口点
.globl _start
_start:
# 计算 bootpagetable 的物理页号(satp 中保存的页表基地址是物理页号)
lui t0, %hi(bootpagetable) # Load Upper Immediate,将立即数的高20位(%hi)加载到t0寄存器的高20位
li t1, 0xffffffff00000000 # Load Immediate,加载立即数到t1
sub t0, t0, t1 # t0 - t1,即将虚拟地址转为物理地址
srli t0, t0, 12 # shift right logical immediate,t0右移12位,即页号PPN
# 设置使用 SV39(8 << 60)
li t1, (8 << 60) # t1 = 2^63,即高四位=8,即MODE=8,即Sv39模式
or t0, t0, t1 # 设置satp的PPN,MODE=8,ASID=0
# 写入 satp 并刷新 TLB
csrw satp, t0 # 写satp
sfence.vma # 刷新TLB,使新配置页表生效
# 加载栈地址,I 型指令只支持最多 32 位立即数,操作地址时需要分两次装载
lui sp, %hi(bootstacktop) # 将栈顶地址高部分加载到sp
addi sp, sp, %lo(bootstacktop) # 将栈顶地址低部分加载到sp
# 跳转到 main
lui t0, %hi(main) # 同理加载main地址
addi t0, t0, %lo(main)
jr t0 # 跳转到main函数
# 以下 4096 × 16 字节的空间作为 OS 的启动栈
.section .stack
.align 12
.global bootstack
bootstack:
.space 4096 * 16
.global bootstacktop
bootstacktop:
# 初始内核映射所用的页表
.section .data
.align 12 # 4K地址对齐
bootpagetable:
.quad 0 # 定义一个8字节的数据项
.quad 0
# 第 2 项:0x80000000 -> 0x80000000,0xcf 表示 VRWXAD 均为 1,该页表项用于支持跳转到 main 之前刷新 TLB 之后的代码工作
.quad (0x80000 << 10) | 0xcf
.zero 507 * 8 # 填充507个8字节的零数据
# 第 510 项:0xffffffff80000000 -> 0x80000000,0xcf 表示 VRWXAD 均为 1
.quad (0x80000 << 10) | 0xcf # PPN | Flags,63~39位等于38位,所以表示 0xffffffff 80000000
.quad 0- 原
entry.S
- 设置内核栈
- 跳转到main函数
- 现
entry.asm
- 我们分别初始化了内核栈(
4096*16Bytes)和内核所使用的映射表空间(512*8Bytes) - 计算物理页号PPN
- 设置
satp寄存器的MODE、PPN - 刷新TLB
- 设置内核栈(写入
sp寄存器) - 跳转到
main函数地址
可能有同学不理解TLB是什么?
CPU 进行地址翻译时,每次都需要在内存中查找页表,但物理内存的速度比 CPU 的速度慢得多。譬如一个取指的过程,原本就只需要一次访存,使用地址翻译后竟需要四次访存才能将指令加载到寄存器,这样无疑大大拖慢的运行效率。
CPU 为了加速地址翻译的过程,在内部设立了一个元器件**快表(TLB)**,来缓存最近访问过的页表项。由于局部性原理,当我们需要查询一个映射时,会有很大可能这个映射在近期被查询过,保存在 TLB 中,所以我们可以先到 TLB 里面去查一下,如果有的话我们就可以直接完成映射,而不用访问那么多次内存了。
但如果我们修改了 satp 寄存器,切换到了一个不同的页表,TLB并不会自动刷新,此时的虚拟地址和原先的虚拟地址对应的页表项不同,即这时 TLB 中缓存的页表项仍然是旧页表的页表项,再次访存就可能出现错误。这个时候我们就需要使用指令 `sfence.vma` 来手动刷新 TLB。- 这里我们使用的就是大页机制来设立页表,页表的第 510 项将以
0xffffffff80000000开头的 1G 字节虚拟地址空间映射到了以0x80000000开头的物理地址空间,同时0xcf设置了该页表项的属性(不全为0,说明是指向最终的物理页)。 - 我们注意到,在页表中还有一项
0x80000000到0x80000000的映射,这是因为从刷新 TLB 后,内核开始运行在高地址空间,取指访存等都按照0xffffffff80000000到0x80000000来进行,但是此时 sp 指针的值未被刷新,其中仍然是低地址,取指时就会发生错误。这一条映射就是临时为这段代码的取址准备的。而在跳转之后,跳转指令会将sp设置为main符号的地址,而这个地址是高地址,就不会产生问题了。 - 重新运行一下,我们的输出对比上一章不会有变化,这说明内核已经安全地运行在了虚拟地址空间了。
4.2 实现页表
1、定义一些结构体和常量来管理页表操作
- 一个页表项占据 8 字节,也就是宽 64 位,正好和一个
usize宽度对应。而一个页表也就是一个 512 个页表项组成的大数组。我们可以将这些结构抽象成结构体,方便操作。 - 页表项标志位常量
// kernel/mapping.h
typedef usize PageTableEntry; /* 页表项长度 64 位 */
/*
* 页表由页表项组成
* 页大小为4096字节,一项PTE大小为8字节,故 4096/8
*/
typedef struct
{
PageTableEntry entries[PAGE_SIZE >> 3]; // 一页页表中包含 4096 / 8 个页表项
} PageTable;
/* 页表项的 8 个标志位 */
#define VALID 1 << 0
#define READABLE 1 << 1
#define WRITABLE 1 << 2
#define EXECUTABLE 1 << 3
#define USER 1 << 4
#define GLOBAL 1 << 5
#define ACCESSED 1 << 6
#define DIRTY 1 << 7- 定义一个函数,用于从一个虚拟页号中提取各级别的页号
/*
* 根据虚拟页号得到其对应页表项在三级页表中的位置
* 输入:vpn-27位虚拟页号VPN,存放三级页表索引的数组
*/
void
getVpnLevels(usize vpn, usize *levels)
{
levels[0] = (vpn >> 18) & 0x1ff;
levels[1] = (vpn >> 9) & 0x1ff;
levels[2] = vpn & 0x1ff;
}2、定义一些辅助结构体来描述映射行为
// kernel/mapping.h
// 映射片段,描述映射到虚拟内存的一个段
typedef struct
{
/* 映射虚拟地址范围 */
usize startVaddr;
usize endVaddr;
/* 该段映射的权限 */
usize flags;
} Segment;
/* 一个虚拟地址空间,可能映射了多个段 */
typedef struct
{
usize rootPpn; /* 根页表的物理页号 */
} Mapping;Segment描述的是一段内存的映射,如内核的某个段的映射,但是一个虚拟地址空间可能不止映射一个段,所以定义Mapping结构,来描述某一个独立的地址空间。描述一个地址空间只需要保存根页表的物理页号就好了,因为这是切换到该地址空间唯一需要的数据。
3、映射实现,findEntry(),用于在一个页表中找到对应虚拟页号所表示的页表项,并返回其地址,这样我们就可以方便地寻找修改了
// kernel/mapping.c
/*
* 根据给定的虚拟页号寻找三级页表项
* 如果某一级页表项为空,会创建下一级页表并填充
* 输入:self-44位根页表物理页号PPN,vpn-27位虚拟页号VPN
* 输出:一级页表页表项
*/
PageTableEntry
*findEntry(Mapping self, usize vpn)
{
// 获得 根页表 线性映射后的虚拟地址
PageTable *rootTable = (PageTable *)accessVaViaPa(self.rootPpn << 12);
// 计算虚拟页号对应三级页表位置
usize levels[3];
getVpnLevels(vpn, levels);
// 计算获取三级页表项PTE
PageTableEntry *entry = &(rootTable->entries[levels[0]]);
int i;
for(i = 1; i <= 2; i ++) {
/* 页表不存在,创建新页表 */
if(*entry == 0) {
usize newPpn = allocFrame() >> 12; // 分配一个空闲物理页,返回分配页物理地址
*entry = (newPpn << 10) | VALID; // 设置页表项指向分配页,并设置Flags有效位
}
// 计算下一级页表位置,PTE获取高44位,左移两位对应的页即为其物理地址
usize nextPageAddr = (*entry & PDE_MASK) << 2;
// 索引下一级页表的页表项PTE
// 注意!从页表和页表项中取出的地址都是物理地址,但内核已经被映射到了高地址空间,所以只能通过虚拟地址来访问
entry = &(((PageTable *)accessVaViaPa(nextPageAddr))->entries[levels[i]]);
}
return entry;
}- 若出现下一级页表不存在的情况,通过
allocFrame()函数就能直接分配一个空闲物理页作为页表。 - 其中,
PDE_MASK用于从页表项中取出物理页号:
//kernel/consts.h
// 从 PageTableEntry 中获取物理页号
#define PDE_MASK 0x003ffffffffffC00- 注意我们从页表和页表项中取出的地址都是物理地址,但是由于内核已经被初始映射到了高地址空间,我们只能通过虚拟地址来实际访问,好在初始映射是线性映射,我们可以很容易地手动转换:
// kernel/mapping.c
// 获得线性映射后的虚拟地址
usize
accessVaViaPa(usize pa)
{
return pa + KERNEL_MAP_OFFSET;
}4、findEntry()基本是整个页表实现中最核心的函数,其余的函数就是一些数据结构的创建和简单处理了。
// kernel/mapping.c
/*
* 创建一个有根页表的映射,只分配了三级页表的空间
* 输出:根页表的物理页号PPN
*/
Mapping
newMapping()
{
usize rootPaddr = allocFrame();
Mapping m = {rootPaddr >> 12};
return m;
}
/*
* 将页表地址写入 satp 中
* 设置 satp 为 SV39,并刷新 TLB
*/
void
activateMapping(Mapping self)
{
usize satp = self.rootPpn | (8L << 60); // 设置 PPN 和 MODE
asm volatile("csrw satp, %0" : : "r" (satp));
asm volatile("sfence.vma":::);
}- 最后我们需要做的,就是将创建的
Segment,也就是对一个映射的描述,交由一个页表去实现。目前我们只实现线性映射的版本。注意Segment中的起始和结束虚拟地址可能不是 4K 对齐的,我们需要手动对齐一下,随后就是映射这个范围内的所有页了。
// kernel/mapping.c
/*
* 线性映射一个段到三级页表上
* 段中的每一个虚拟地址都会按照固定偏移量线性映射到一个物理地址
*/
void
mapLinearSegment(Mapping self, Segment segment)
{
usize startVpn = segment.startVaddr / PAGE_SIZE; // 段起始页虚拟页号VPN(4K对齐)
usize endVpn = (segment.endVaddr - 1) / PAGE_SIZE + 1; // 段结束页虚拟页号VPN(4K对齐)
usize vpn;
for(vpn = startVpn; vpn < endVpn; vpn ++) {
PageTableEntry *entry = findEntry(self, vpn);
if(*entry != 0) {
panic("Virtual address already mapped!\n");
}
// 修改三级页表映射到实际物理地址上,并设置flags权限,及有效位
*entry = ((vpn - KERNEL_PAGE_OFFSET) << 10) | segment.flags | VALID;
}
}4.3 内核重映射
1、我们在4.1节用大页的方式将内核部分的代码和数据映射到了高地址空间,但是这个映射非常粗糙,我们将一整个大页,1G 字节的内存都设置为同样的权限,即可读、可写、可执行。这自然是很不安全的。在链接脚本中,我们将内核划分为多个段,段之间的权限各不相同:
- .text 段用于保存内核代码,可读可执行,不可写
- .rodata 段保存只读数据,可读,不可写不可执行
- .data 段用于保存普通数据,可读可写,不可执行
- .bss 段用于保存全局变量,可读可写,不可执行
我们在链接脚本中定义了各个段的起始符号,像引用外部函数一样引用它们就可以直接使用这些符号
// kernel/consts.h
// 链接脚本的相关符号
extern void kernel_start();
extern void text_start();
extern void rodata_start();
extern void data_start();
extern void bss_start();
extern void kernel_end();2、将内核各个段映射到页表上
// kernel/mapping.c
/*
* 创建一个映射了内核的虚拟地址空间
* 在该地址空间中,内核的各个段按照固定的偏移被映射到虚拟地址空间的高地址空间处
*/
Mapping
newKernelMapping()
{
Mapping m = newMapping(); // 创建根页表
/* .text 段,r-x */
Segment text = {
(usize)text_start,
(usize)rodata_start,
1L | READABLE | EXECUTABLE
};
mapLinearSegment(m, text); // 将段映射到三级页表上
/* .rodata 段,r-- */
Segment rodata = {
(usize)rodata_start,
(usize)data_start,
1L | READABLE
};
mapLinearSegment(m, rodata);
/* .data 段,rw- */
Segment data = {
(usize)data_start,
(usize)bss_start,
1L | READABLE | WRITABLE
};
mapLinearSegment(m, data);
/* .bss 段,rw- */
Segment bss = {
(usize)bss_start,
(usize)kernel_end,
1L | READABLE | WRITABLE
};
mapLinearSegment(m, bss);
/* 剩余空间,rw- */ // 内核结束到内存结束空间,按页分配内存分配的就是这一段空间
Segment other = {
(usize)kernel_end,
(usize)(MEMORY_END_PADDR + KERNEL_MAP_OFFSET),
1L | READABLE | WRITABLE
};
mapLinearSegment(m, other);
return m;
}- 注意我们除了要映射那四个段以外,还需要映射从内核结束到内存结束的物理地址空间,因为我们按页分配内存分配的就是这一段内存,所以这一段的权限也需要设定为可读可写。
- 注意我们没有直接将映射好的页表设置生效,而是将它返回了,原因是可能有些地址空间除了需要映射内核以外,还可能需要映射其他的段,譬如进程的地址空间就还需要映射进程自己的代码和数据
- 最后我们就只需要将设置好的页表基地址写入 satp,设置生效就好了!
// kernel/mapping.c
/* 重映射内核,写入satp */
void
mapKernel()
{
Mapping m = newKernelMapping(); // 创建一个映射了内核的虚拟地址空间
activateMapping(m); // 将根页表地址写入 satp
printf("***** Remap Kernel *****\n");
}- 将
mapping加入Makefile中编译,我们在main()函数initMemory()后调用这个函数,为了验证我们没出什么岔子,我们可以在映射结束后再输出一句话。
// kernel/main.c
void main()
{
extern void initInterrupt(); initInterrupt(); // 设置中断处理程序入口 和 模式
extern void initTimer(); initTimer(); // 时钟中断初始化
extern void initMemory(); initMemory(); // 初始化 页分配 和 动态内存分配
extern void mapKernel(); mapKernel(); // 内核重映射,三级页表机制
printf("Safe and sound!\n");
// testAlloc();
// asm volatile("ebreak" :::); // 手动触发一个中断
// printf("return from ebreak\n");
// extern void initHeap(); initHeap();
// extern void testHeap(); testHeap();
while(1) {}
}- 得到如下输出:
==== Init Interrupt ====
***** Init Memory *****
***** Remap Kernel *****
Safe and sound!
** TICKS = 100 **
** TICKS = 200 **